
LLM Wiki:Karpathy 提出的知识管理新范式
llm-wiki-karpathy-knowledge-management
从 RAG 到”会进化的 Wiki”
著名 AI 学者 Andrej Karpathy 发布了一篇名为《LLM Wiki》的”构思文件”(Idea File)。它提出了一种不同于传统 RAG(检索增强生成)的知识管理新范式,旨在利用 LLM 构建一个能够自我维护、持续演进且具备累积效应的知识库。
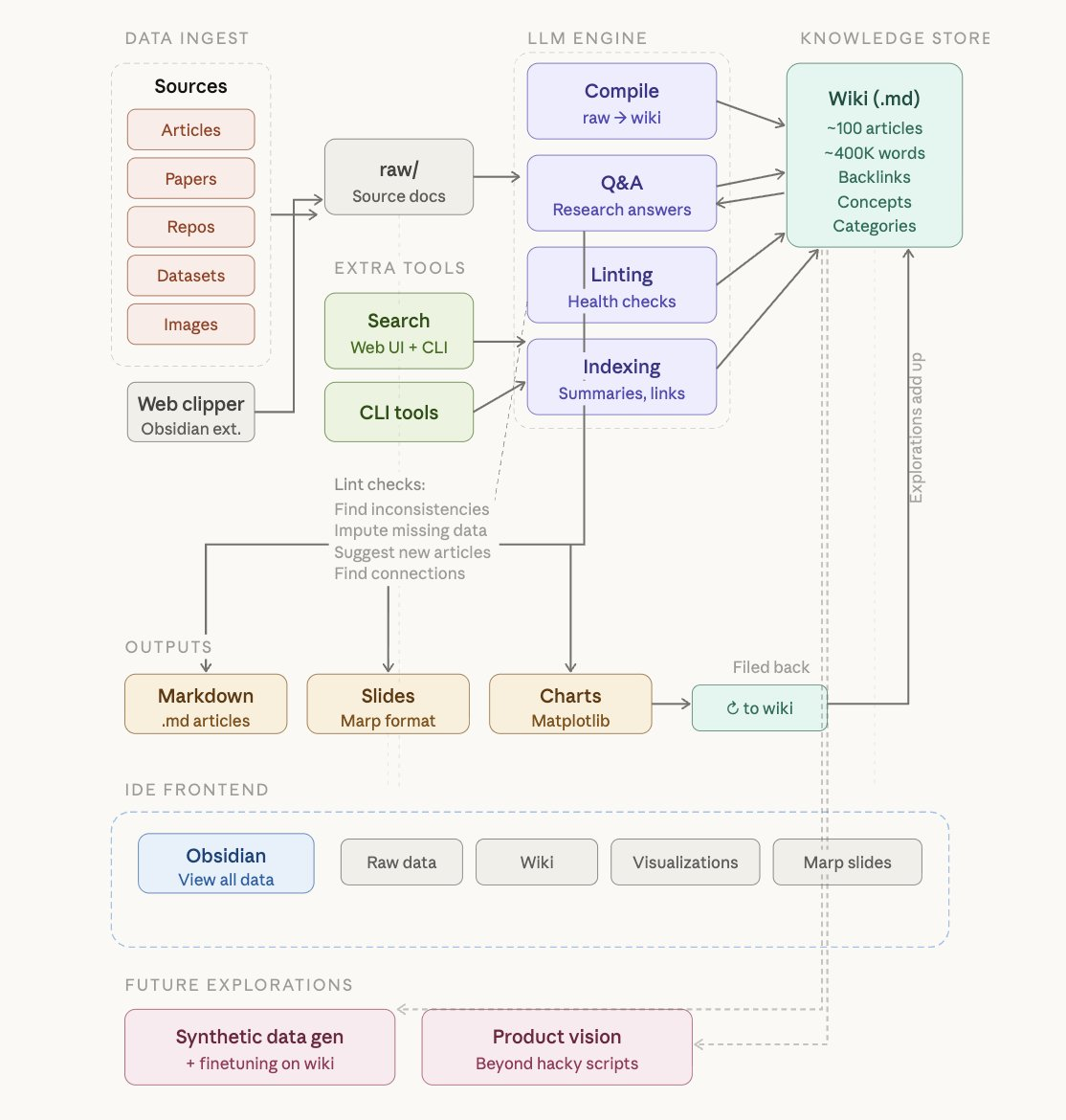
Karpathy 指出,目前的 RAG 系统(如 NotebookLM 或 ChatGPT 文件上传)本质上是”临时工”:
传统 RAG 的局限:每次提问时,模型都要重新从海量碎片中检索并拼凑答案,知识没有积淀。
LLM Wiki 的愿景:将 LLM 作为”维基百科编辑”,把原始资料(PDF、对话记录、论文)转化为结构化的 Markdown 页面。LLM 不仅是检索器,更是知识的组织者,它通过实体链接、冲突检测和持续合成,让知识库随着时间的推移变得越来越深厚。
运作机制:四个关键周期
Karpathy 在文中详细描述了系统的四个运作环节:
1. 摄取(Ingest)
每增加一个新源(Source),LLM 会自动更新相关的 10-15 个 Wiki 页面,维护索引(index.md)并更新日志。
2. 查询(Query)
查询结果不再是阅后即焚,而是会被固化为新的 Wiki 页面,实现知识的”复利效应”。
3. 维护(Lint)
LLM 定期检查知识库的健康状态,如发现矛盾、填补信息鸿沟、清理孤立页面等。
4. 分发(Distribute)
将沉淀的结构化知识转化为幻灯片、播客脚本或可视化图表。
社区反馈与观点
评论区(及相关讨论)对这一概念表现出极高的热情,主要集中在以下几点:
效率与成本:许多开发者认为这比维护复杂的向量数据库更简单且廉价(95% 的成本削减),因为它直接基于文本文件和文件系统。
实现路径:评论中提到,这种模式非常适合配合 Claude Code 或 Cursor 等具备强文件操作能力的 AI Agent 使用。甚至有人已经用 Obsidian 结合 LLM 实现了类似的”第二大脑”。
知识主权:用户普遍赞赏这种”纯 Markdown”的透明性。与闭源的知识库不同,Markdown 文件是人类可读的,且不被任何特定供应商锁定。
局限性讨论:部分评论担忧在极大规模数据下,LLM 维护 Wiki 的 Token 消耗和同步复杂性,认为这更适合个人或小团队的深度知识管理。
总结
Karpathy 的这个 Gist 不仅仅是一个技术方案,更是一种知识管理哲学。他倡导将 AI 从一个”问答工具”转变为一个”持续学习的系统”,让数字资产从零散的”堆料”变成有生命、能生长的”有机体”。这为个人知识管理和企业知识沉淀提供了一个极其有力的参考模板。
📄 原文链接: https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
🍄 Mycelium 将持续跟踪 LLM Wiki 等相关框架的发展,并进行实际实验测试,为大家筛选出最优的知识管理方案。敬请关注后续实验文章!
💬 评论与讨论
使用 GitHub 账号登录后发表评论